Ujorm3: A New Lightweight ORM for JavaBeans and Records
Learn about Ujorm3, a new lightweight Java ORM for JavaBeans and Records. Enjoy type-safe native SQL mapping, zero reflection, and high performance.
Join the DZone community and get the full member experience.
Join For Free"Do the simplest thing that could possibly work."
— Kent Beck, creator of Extreme Programming and pioneer of Test-Driven Development.
I believe the Java language architects didn't exactly hit the mark when designing the API for the original JDBC library for database operations. As a result, a significant number of various libraries and frameworks have emerged in the Java ecosystem, differing in their approach, level of complexity, and quality.
I would like to introduce you to a brand-new lightweight ORM library, Ujorm3, which I believe beats the competition thanks to its simplicity, transparent behavior, and low overhead. The goal of this project is to offer a reliable, safe, efficient, and easy-to-understand tool for working with relational databases without hidden magic and complex abstractions that often complicate both debugging and performance. The final release is now available in the Maven Central Repository, released under the free Apache License 2.0.
The library builds on the familiar principles of JDBC but adds a thin layer of a user-friendly API on top. It works with clean, stateless objects and native SQL, so the developer has full control over what is actually executed in the database. Ujorm3 deliberately avoids implementing SQL dialects and instead uses native SQL complemented by type-safe tools for mapping database results to Java objects. It does not cache the results of any user queries. To achieve maximum speed, however, Ujorm3 retains certain metadata.
Application API Classes
The library offers a type-safe SelectQuery builder for constructing SQL SELECT queries smoothly in Java, while still fully supporting the classic SqlQuery for writing raw native SQL. Both approaches utilize the generated Meta classes for mapping and aliases, preventing SQL typos and ensuring compile-time safety. The SelectQuery automatically generates JOIN clauses based on the entity metadata. The type of join is determined by the @JoinColumn annotation:
- INNER JOIN: Used when the attribute is marked as mandatory (e.g.,
@JoinColumn(nullable = false)). - LEFT JOIN: Used by default or when the attribute is explicitly marked as nullable (e.g.,
@Nullableor@JoinColumn(nullable = true)).
Data filtering can be defined using the where() method, which accepts a Criterion object. This object can represent a complex logical structure in the form of a binary tree, providing a clear and type-safe way to build nested conditions.
Automatically generated Meta* classes enable safe column mapping without the use of typo-prone text strings. The use of a SELECT statement can then look like this, for example:
final EntityContext CTX = EntityContext.ofDefault();
final EntityManager<Employee, Long> EMPLOYEE_EM = CTX.entityManager(Employee.class);
List<Employee> select() {
return SelectQuery.run(connection(), EMPLOYEE_EM, query -> query
.sql("SELECT") // Optional: "SELECT" is the default
.columnsOfDomain(true)
.column(MetaEmployee.city, MetaCity.name) // INNER JOIN (nullable = false)
.column(MetaEmployee.city, MetaCity.countryCode)
.column(MetaEmployee.boss, MetaEmployee.name) // LEFT JOIN (nullable = true)
.where(MetaEmployee.id.whereGe(1L))
.tail("ORDER BY", MetaEmployee.id)
.toList()
);
}If you need full control over building the SQL SELECT statement, use the SqlQuery class. This class provides an API with methods for type-safe insertion of database columns or just their labels. The individual approaches differ only in the way the SQL query is constructed. Regardless of the chosen approach, the database columns are ultimately mapped to entities using column aliases in the format: "city.name". The resulting ResultSet is also mapped to entities using this same mechanism via the ResultSetMapper class.
The EntityManager is used for working with entities, providing simple CRUD operations — including batch commands — through a Crud object. An interesting feature is the possibility of partial updates — the developer can specify an enumeration of columns to be updated, or pass the original object to the library, from which it will infer the changes itself. The mentioned classes are illustrated in a simplified class diagram. All listed methods are public:
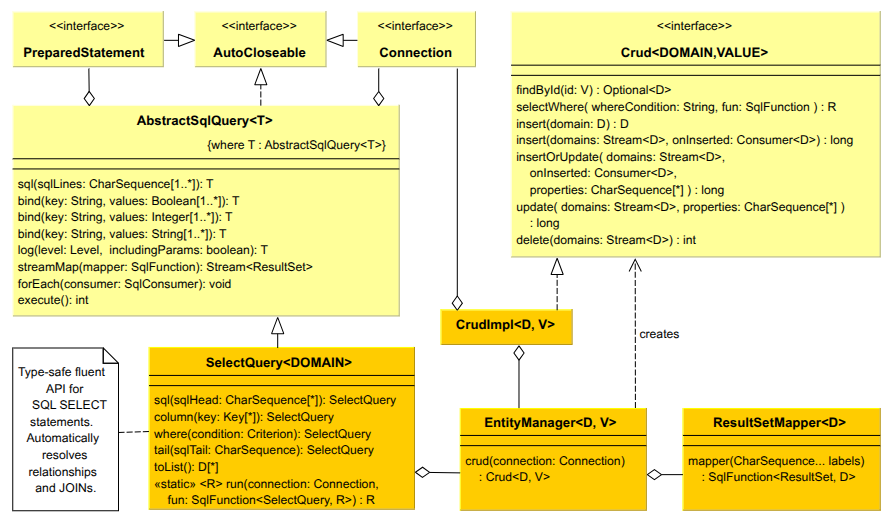
Performance
Ujorm3 achieves great results in benchmark tests, where it is compared with some popular ORM libraries. The mechanism of writing values to domain objects also contributes to the good score. Instead of the traditional approach using Java reflection, the library generates and compiles its own classes at runtime. Such an approach generally reduces memory requirements, minimizes overhead, and saves work for the Garbage Collector. The library has no dependencies on external libraries, and the compiled benchmark module (including the Ujorm3 library itself) is less than 3 MB, which is advantageous for microservices and embedded environments. However, it is good to keep in mind that in a production environment, in conjunction with slower databases, the differences in performance may partially blur.
Getting Started
To try the library in your Java 17+ project, simply add the dependency to your Maven configuration:
<dependency>
<groupId>org.ujorm</groupId>
<artifactId>ujo-core</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.ujorm</groupId>
<artifactId>ujorm-orm</artifactId>
<version>3.0.0</version>
</dependency>
To automatically generate metamodel classes, add the optional APT configuration to the build element:
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.14.1</version>
<configuration>
<annotationProcessorPaths>
<path>
<groupId>org.ujorm</groupId>
<artifactId>ujorm-meta-processor</artifactId>
<version>3.0.0</version>
</path>
</annotationProcessorPaths>
</configuration>
</plugin>
</plugins>The Ujorm module from the Benchmark project can be used as a template for a sample implementation. The library's codebase is currently covered by JUnit tests that utilize an in-memory H2 database (in addition to mocked objects). Before releasing the final version, I plan to add integration tests for PostgreSQL, MySQL, Oracle, and MS SQL Server databases.
Useful Links
Published at DZone with permission of Pavel Ponec. See the original article here.
Opinions expressed by DZone contributors are their own.
Comments