Why Your RAG Pipeline Will Fail Without an MCP Server
RAG was supposed to fix hallucinations. Instead, it quietly introduced a new class of production failures nobody warned you about.
Join the DZone community and get the full member experience.
Join For FreeLet’s unpack the uncomfortable truth:
most Retrieval-Augmented Generation (RAG) systems in production today are fragile, expensive, and deceptively incomplete.
Not because vector databases are flawed. Not because LLMs are unreliable.
But because you’re missing the control plane that orchestrates intelligence itself.
That missing piece?
An MCP Server (Model Context Protocol Server).
The Illusion of “Working” RAG
Your pipeline probably looks like this:
User Query → Embed → Vector DB → Top-K Results → Prompt → LLM → ResponseIt works in demos. It even passes initial tests.
Then production happens.
Suddenly:
- Answers become inconsistent
- Costs spike unpredictably
- Latency creeps into seconds
- Hallucinations return in subtle, dangerous ways
And you start tuning:
- Top-K values
- Chunk sizes
- Embedding models
But the problem isn’t tuning. The problem is orchestration.
What RAG Actually Needs (But Doesn’t Have)
A real-world RAG system isn’t just retrieval + generation. It’s:
- Context selection
- Context ranking
- Context transformation
- Tool invocation
- Policy enforcement
- Memory management
Traditional RAG pipelines treat all of this as inline logic inside application code.
That’s like:
Running Kubernetes workloads… without Kubernetes.
Enter MCP: The Missing Control Plane
An MCP server acts as the control plane for context and reasoning, sitting between your application and LLM.
Instead of this:
App → Vector DB → LLMYou get:
App → MCP Server → (Retrieval + Tools + Policies + Memory) → LLMThink of MCP as:
- Envoy for prompts
- Kubernetes for context
- OPA for AI decisions
Failure Modes of RAG (Without MCP)
Let’s walk through real production failures.
1. Naive Retrieval = Wrong Context
Problem:
Vector search returns similar, not relevant results.
- Irrelevant chunks sneak in
- Critical context is missing
- LLM confidently answers incorrectly
Without MCP:
You rely on:
- Top-K tuning
- Embedding tweaks
With MCP:
You introduce:
- Multi-stage retrieval (semantic + keyword + metadata filters)
- Context re-ranking (cross-encoders)
- Dynamic query rewriting
MCP orchestrates retrieval like a pipeline, not a single step.
2. Context Overload (Token Explosion)
Problem:
You shove too much context into the prompt.
Result:
- Higher costs
- Slower responses
- Diluted signal
Without MCP:
You:
- Reduce chunk size
- Limit Top-K
- Hope for the best
With MCP:
You get:
- Context compression
- Deduplication
- Relevance scoring
- Token budgeting
MCP treats tokens like a scarce resource, not an afterthought.
3. No Reasoning Orchestration
Problem:
RAG assumes:
“Retrieve → Answer”
Reality:
Some queries need:
- Multi-hop reasoning
- Tool usage (APIs, DBs)
- Clarification steps
Without MCP:
You hardcode logic or ignore complexity.
With MCP:
You enable:
- Tool calling pipelines
- Chain-of-thought orchestration
- Conditional execution flows
MCP turns RAG into a reasoning system, not just retrieval.
4. Zero Security Boundaries
Problem:
Your LLM blindly trusts retrieved context.
Attack vectors:
- Prompt injection
- Data poisoning
- Sensitive data leakage
Without MCP:
Security is bolted on (if at all).
With MCP:
You enforce:
- Context sanitization
- Policy checks (OPA-style)
- Tool access control
- Output filtering
MCP becomes your AI firewall.
5. No Observability Into “Why It Failed”
Problem:
When RAG fails, you don’t know:
- Which chunk caused it
- Why it was selected
- How the prompt evolved
Without MCP:
Debugging = guesswork.
With MCP:
You get:
- Context lineage tracing
- Prompt versioning
- Retrieval metrics
- Token usage insights
MCP gives you distributed tracing for intelligence.
Reference Architecture: RAG + MCP
Here’s what a production-grade system looks like:
┌──────────────────────┐
│ Application │
└─────────┬────────────┘
│
▼
┌──────────────────────┐
│ MCP Server │
│----------------------│
│ Context Orchestrator │
│ Retrieval Pipeline │
│ Tool Router │
│ Policy Engine │
│ Memory Manager │
└─────────┬────────────┘
│
┌─────────────────┼─────────────────┐
▼ ▼ ▼
Vector DB External APIs Cache Layer
(Pinecone, (Tools, DBs) (Redis)
Weaviate)
│
▼
LLM Providers
(OpenAI, Gemini, Claude, etc.)Example: MCP-Orchestrated Retrieval (Pseudo-Code)
Instead of:
results = vector_db.search(query)
response = llm.generate(results)You get:
context = mcp.retrieve(
query=query,
strategy=[
"semantic_search",
"keyword_filter",
"rerank"
],
constraints={
"max_tokens": 2000,
"sensitivity": "low"
}
)
tools = mcp.select_tools(query)
response = mcp.generate(
context=context,
tools=tools,
policies=["no_sensitive_data"]
)Notice the shift: From function calls → to intent-driven orchestration
Performance and Cost Reality
Without MCP:
- Over-fetching context → ↑ token cost
- Poor ranking → ↑ retries
- No caching → ↑ latency
With MCP:
- Smart caching (context + embeddings)
- Token-aware pipelines
- Adaptive retrieval
Teams report:
- 30–60% cost reduction
- 2–3x latency improvement
- Significant accuracy gains
Production Lessons (Hard-Earned)
From real-world systems:
❌ Anti-patterns
- Treating RAG as a "feature"
- Embedding everything blindly
- Ignoring context lifecycle
✅ What Works
- MCP as a first-class platform component
- Separation of:
- retrieval
- reasoning
- generation
- Policy-driven AI pipelines
The Bigger Shift: From RAG to RAG++
RAG was step one.
MCP enables the next evolution:
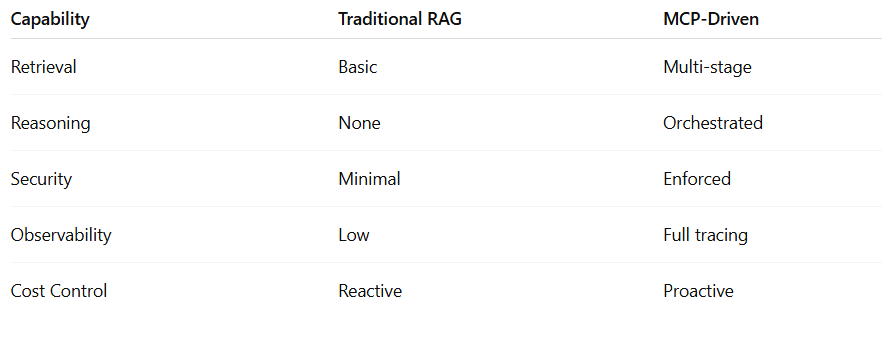
This isn’t an optimization. It’s an architectural shift.
Final Thought
RAG pipelines fail not because they retrieve the wrong data.
They fail because:
They don’t control how context is selected, shaped, secured, and used.
That control layer is no longer optional. It’s your MCP server.
If you're building RAG systems in production and seeing:
- inconsistent responses
- rising costs
- unexplained failures
You don’t need better prompts. You need a better control plane.
Start by designing your MCP layer.
Or go one step further:
Build a production-grade MCP server on Kubernetes with observability, policy enforcement, and multi-LLM routing.
Opinions expressed by DZone contributors are their own.
Comments