AutoML vs. LLMs: A Developer’s Guide to Efficient ML Pipeline Generation
While large language models (LLMs) dominate the AI conversation, AutoML remains the king for structured data. Here’s how to choose the right tool for your infrastructure.
Join the DZone community and get the full member experience.
Join For FreeIn the current AI landscape, the hype cycle is undeniably focused on large language models (LLMs). From code generation to reasoning, models like GPT-4 and Llama 3 have transformed how we interact with data. However, for machine learning (ML) engineers tasked with building robust, production-grade pipelines for tabular data or predictive analytics, LLMs are not always the silver bullet.
Automated Machine Learning (AutoML) has quietly matured into a powerhouse technology, automating the tedious aspects of data science — feature engineering, model selection, and hyperparameter tuning.
Based on extensive comparative analysis, this article explores the distinct strengths of AutoML versus LLMs in pipeline generation, analyzing performance, cost, and interpretability to help you architect the most efficient solution.
The Two Approaches to Pipeline Generation
Before diving into the benchmarks, let’s distinguish how these two technologies approach the creation of an ML workflow.
1. AutoML: The Specialized Engineer
AutoML frameworks (such as TPOT, H2O, or Auto-Keras) focus on algorithmic search. They treat the ML pipeline as a search space optimization problem.
- Workflow: Data Analysis → Feature Selection → Model Selection → Hyperparameter Tuning.
- Goal: Find the mathematically optimal pipeline for a specific dataset.
- Tools: Auto-Sklearn, Auto-PyTorch, AutoGluon.
2. LLMs: The Generative Architect
LLMs approach pipeline generation via code synthesis and semantic understanding. They act as controllers that generate the code required to build the pipeline, rather than executing the search themselves.
- Workflow: Prompt Engineering → Code Generation → Execution → Pipeline Assembly.
- Goal: Generate human-readable code that can solve the problem, often leveraging reasoning to select models.
- Tools: GPT-4, StarCoder, CodeLlama.
Comparative Analysis: Performance and Resources
When evaluating these technologies for enterprise adoption, we analyze them across four critical dimensions: performance, interpretability, cost, and latency.
1. Performance and Versatility
LLMs excel in few-shot and zero-shot learning, particularly in natural language processing (NLP) tasks. If your pipeline involves sentiment analysis or text summarization, an LLM is the clear winner.
However, for structured data (tabular classification and regression), AutoML consistently outperforms LLMs. AutoML tools use genetic programming or Bayesian optimization to ensemble multiple models (for example, stacking XGBoost with a neural network), a level of complexity that LLMs struggle to architect purely through code generation.
2. Interpretability (The Black Box Problem)
For regulated industries such as finance and healthcare, interpretability is non-negotiable.
- AutoML: Generally offers high transparency. Tools like TPOT provide the exact Python code for the best pipeline. Furthermore, AutoML models are compatible with post-hoc explainability tools like SHAP (SHapley Additive exPlanations) and LIME.
- LLMs: Notoriously difficult to interpret. While we can visualize attention heads to infer which tokens the model focused on, mapping this behavior to specific decision logic is abstract and often unintuitive.
Figure 1: Complexity of LLM Attention Mechanisms
(Conceptual representation of Attention Heads in Transformer models, capturing lexical patterns but lacking direct causal explainability compared to feature importance charts.)
3. Training and Inference Cost
This is the most significant differentiator.
- AutoML: Resource-efficient. It can often run on standard CPU clusters. Once the pipeline is identified, the resulting model is usually lightweight (for example, a random forest) with millisecond-level inference times.
- LLMs: Computationally expensive. Training requires massive clusters of GPUs or TPUs, and inference is slow due to the sheer size of the model parameters (billions versus thousands).
Summary of Findings
| Feature | AutoML | Large Language Models (LLMs) |
| Primary Use Case | Structured Data, Tabular Prediction | NLP, Code Gen, Reasoning |
| Performance | High (for specific tasks) | State-of-the-art (for NLP) |
| Interpretability | High (White-box/Grey-box) | Moderate/Low (Black-box) |
| Inference Cost | Low | High |
| Response Time | Real-time (<100ms) | Latency prone (>500ms) |
Implementation: Code Comparison
To visualize the difference, let’s examine how a developer interacts with each approach to generate a pipeline.
The AutoML Approach (Using TPOT)
AutoML handles the complexity internally. You pass in the data, and it returns the optimized model.
from tpot import TPOTClassifier
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_digits
# 1. Load Data
digits = load_digits()
X_train, X_test, y_train, y_test = train_test_split(digits.data, digits.target,
train_size=0.75, test_size=0.25)
# 2. Initialize AutoML
# The 'generations' parameter controls the depth of the search
tpot = TPOTClassifier(generations=5, population_size=20, verbosity=2)
# 3. Fit (AutoML handles feature selection and model tuning here)
tpot.fit(X_train, y_train)
# 4. Export the optimized pipeline code
tpot.export('tpot_digits_pipeline.py')The LLM Approach (Concept)
With an LLM, the “pipeline” is generated text that must be validated and executed.
Prompt:
"Write a Python script using scikit-learn to classify the Digits dataset.
Include feature scaling and try both SVM and Random Forest.
Use GridSearch for hyperparameter tuning."
Output (Code):
... imports ...
pipeline = Pipeline([
('scaler', StandardScaler()),
('clf', RandomForestClassifier())
])
... code to run grid search ...Note: The LLM relies on the user to know that scaling is needed or that GridSearch is the right strategy. AutoML discovers this automatically.
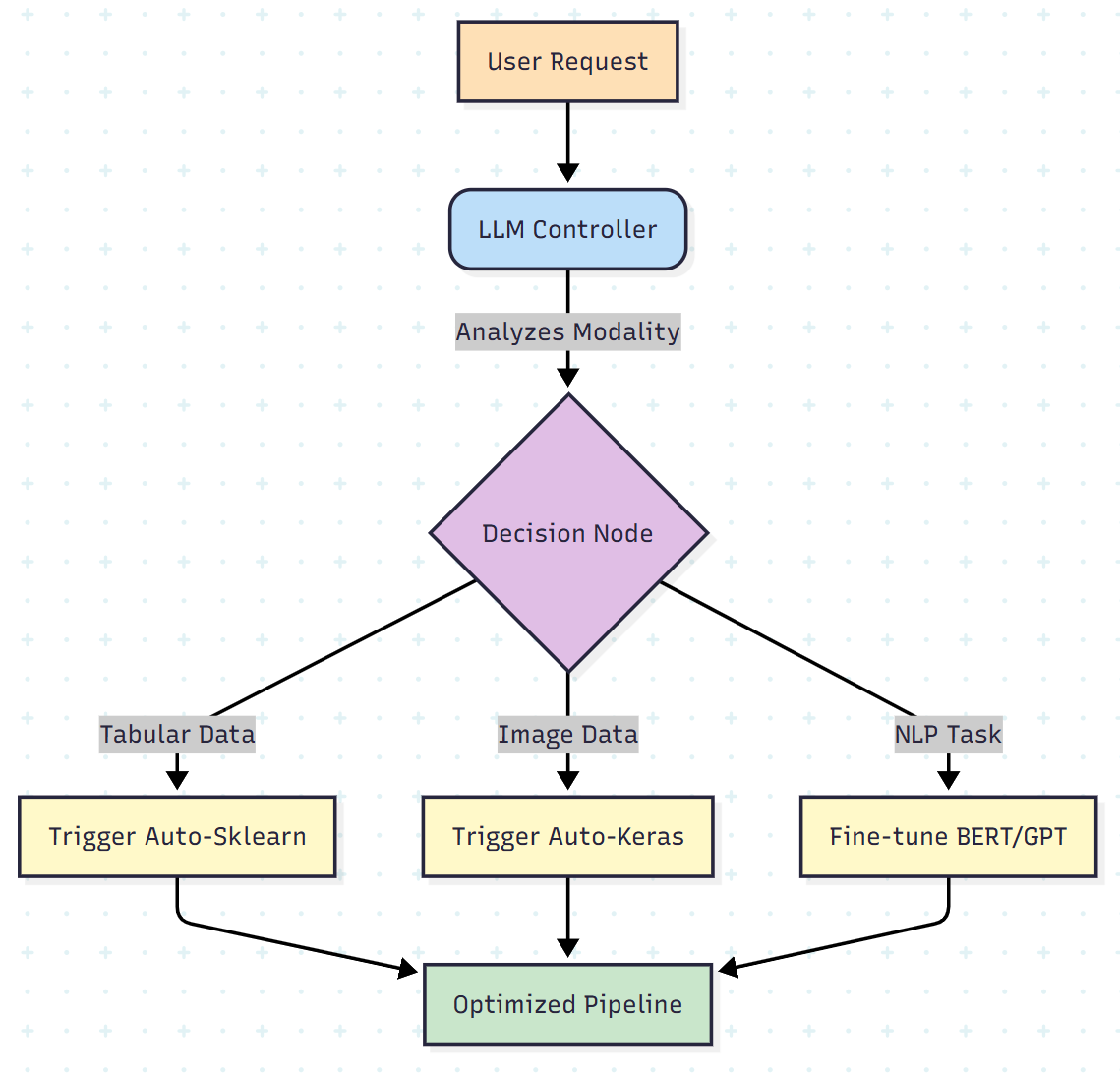
The Future: AutoM3L (Hybrid Architectures)
The research suggests the future is not binary. We are moving toward AutoM3L (Automated Multimodal Machine Learning).
In this architecture, LLMs act as controllers or orchestrators. The LLM analyzes the user’s request and data modality (image, text, audio) and then selects the appropriate AutoML tool to perform the heavy lifting.
Conclusion
While LLMs are transforming software development, they are not the most efficient engine for every machine learning task.
- Choose AutoML if you work with structured data, require low-latency inference, need strict interpretability, or operate in resource-constrained environments.
- Choose LLMs if you process unstructured text, require generative capabilities, or need to synthesize code for complex, non-standard workflows.
For modern DataOps teams, the goal is not to replace AutoML with LLMs, but to use LLMs to make AutoML tools more accessible, interactive, and intelligent.
Opinions expressed by DZone contributors are their own.
Comments